RGB↔X: Image Decomposition and Synthesis Using Material- and Lighting-aware Diffusion Models
Abstract
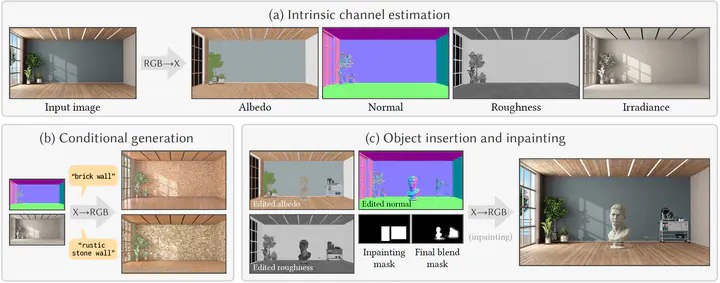
The three areas of realistic forward rendering, per-pixel inverse rendering, and generative image synthesis may seem like separate and unrelated sub-fields of graphics and vision. However, recent work has demonstrated improved estimation of per-pixel intrinsic channels (albedo, roughness, metallicity) based on a diffusion architecture; we call this the RGB→X problem. We further show that the reverse problem of synthesizing realistic images given intrinsic channels, X→RGB, can also be addressed in a diffusion framework. Focusing on the image domain of interior scenes, we introduce an improved diffusion model for RGB→X, which also estimates lighting, as well as the first diffusion X→RGB model capable of synthesizing realistic images from (full or partial) intrinsic channels. Our X→RGB model explores a middle ground between traditional rendering and generative models: we can specify only certain appearance properties that should be followed, and give freedom to the model to hallucinate a plausible version of the rest. This flexibility makes it possible to use a mix of heterogeneous training datasets, which differ in the available channels. We use multiple existing datasets and extend them with our own synthetic and real data, resulting in a model capable of extracting scene properties better than previous work and of generating highly realistic images of interior scenes.