Abstract
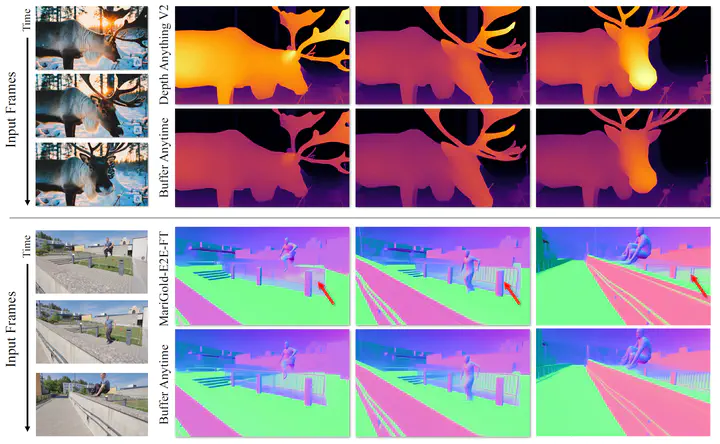
We present Buffer Anytime, a framework for estimation of depth and normal maps (which we call geometric buffers) from video that eliminates the need for paired video–depth and video–normal training data. Instead of relying on large-scale annotated video datasets, we demonstrate high-quality video buffer estimation by leveraging single-image priors with temporal consistency constraints. Our zero-shot training strategy combines state-of-the-art image estimation models based on optical flow smoothness through a hybrid loss function, implemented via a lightweight temporal attention architecture. Applied to leading image models like Depth Anything V2 and Marigold-E2E-FT, our approach significantly improves temporal consistency while maintaining accuracy. Experiments show that our method not only outperforms image-based approaches but also achieves results comparable to state-of-the-art video models trained on large-scale paired video datasets, despite using no such paired video data.